Hallo.
Ich mache nochmal einen eigenen Thread für dieses Problem auf, denn das ist leider was größeres:
Heute war ich seit längerer Zeit mal wieder im Computerraum. Leider stellte sich heraus, dass die Anmeldung (jetzt mit dem v7.2 Server) nicht mehr so funktioniert wie gewohnt: Es dauerte auf den Ubuntu-Clients alles ewig oder funktionierte gar nicht mehr. Bei vielen Schülern erschien auf den Ubuntu-Clients einfach nur „Das hat leider nicht geklappt!“ (ohne genaueres Fehlerbild).
Ein Blick auf den Server zeigt dann aber das Problem:
Der Prozess hängt mit 100% CPU Last fest oder ist so langsam, dass er nicht hinterherkommt, wenn sich ein ganzer Raum auf einmal anmelden will.
Wenn man es alleine versucht, hat man meistens Glück – daher fiel das Verhalten zunächst auch gar nicht auf. Aber wenn eine ganze Klasse kommt, geht nichts mehr.
Die Frage ist natürlich, warum das geschieht bzw durch was der Prozess hängenbleibt?
Habt ihr dieses Problem auch?
Noch eine Beobachtung, die evtl mit diesem Problem zusammenhängt?! Beim Systemstart eines Clients braucht LINBO an der Stelle Initiating machine password update on server 10.16.1.1 sehr lange. Teilweise dauerte das 50 Sekunden, bis es hier weiterging.
Hier übrigens eine ganz ähnliche Beobachtung:
Vielleicht hat ja jemand von Euch eine gute Idee.
Viele Grüße,
Michael
Heute war ich seit längerer Zeit mal wieder im Computerraum. Leider
stellte sich heraus, dass die Anmeldung (jetzt mit dem v7.2 Server)
nicht mehr so funktioniert wie gewohnt:
es wäre mir nicht bekannt, dass da etwas umgestellt worden wäre.
Ich konnte bei meinen Umgebungen keine derartigen Probleme beobachten.
Solange am Client noch der gleiche linuxmuster-linuxclient7 läuft hat
sich sowiso nix an der Anmeldung geändert.
Noch eine Beobachtung, die evtl mit diesem Problem zusammenhängt?! Beim
Systemstart eines Clients braucht LINBO an der Stelle |Initiating
machine password update on server 10.16.1.1| sehr lange. Teilweise
dauerte das 50 Sekunden, bis es hier weiterging.
das könnten auch Netzwerkproblmee sein.
Noch eine andere Frage: wie lange ist den das Upgrade von 7.1 auf 7.2 her?
Wurde nach dem upgrade ein linuxmuster-import-workstations gemacht?
Wurden GPOs verändert?
Ich habe iperf3 bemüht – das zeigt „ganz normal“ 1 GBit/s an … aber das alleine heißt auch noch nicht viel.
Das Update haben wir vor den Sommerferien gemacht, so dass wir zum neuen Schuljahr mit dem v7.2 Server starten konnten. Wir hatten aber zuvor die v7.0 produktiv laufen und haben den Schritt v7.0 → v7.1 → v7.2 in der Testumgebung gemacht und dann direkt den v7.2 Server ausgerollt. Daher können wir produktiv jetzt nur v7.0 und v7.2 miteinander vergleichen.
Das update-Script lief natürlich durch und an den GPOs wurde nichts gemacht.
Ich werde als nächstes das Samba-Log-Level des Servers hochdrehen, um zu sehen, ob man weitere Details erfahren kann…
Das Update haben wir vor den Sommerferien gemacht, so dass wir zum neuen
Schuljahr mit dem v7.2 Server starten konnten. Wir hatten aber zuvor die
v7.0 produktiv laufen und haben den Schritt v7.0 → v7.1 → v7.2 in der
Testumgebung gemacht und dann direkt den v7.2 Server ausgerollt.
wurde den der linuxmuster-linuxclient7 auf den Clients installiert?
aktualisiert?
das ist ein guter Hinweis … weiß ich gerade nicht auswendig, aber das lässt sich morgen schnell klären.
Auf unserem Master-Client habe ich gerade ein Update laufen lassen. Jetzt läuft da dieser linuxmuster-client: linuxmuster-linuxclient7 1.0.8
Der sollte nun aktuell sein. Dann erstelle ich gleich mal ein neues Image und verteile das …
andererseits ist es aber auch so, dass wir in der Zwischenzeit auch einen Jammy-Client ausprobiert hatten. Der zeigte das gleiche Problem, weshalb wir zwischendurch auf fossa zurückgekehrt sind.
Ich nehme daher weiterhin an, dass es irgendein Problem auf dem Server ist?!?
Die Geschichte geht weiter … ich habe den Client nochmal neu in die Domäne aufgenommen mit dem üblichen Befehl linuxmuster-linuxclient7 setup
Zunächst sieht alles gut aus und am Ende wird auch berichtet:
* Successfully enrolled machine in realm
[INFO] It looks like the domain was joined successfully.
Aber dann erscheint:
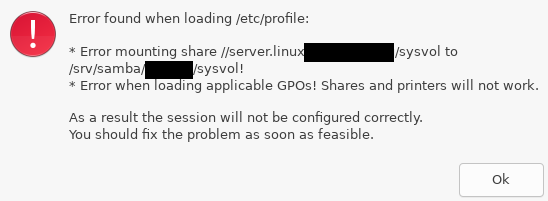
[DEBUG] Calculating mountpoint of //server.linuxmuster.meine-schule.de/sysvol
[WARNING] Uid could not be found! Continuing anyway!
[DEBUG] Trying to mount '//server.linuxmuster.meine-schule.de/sysvol' to '/srv/samba/VM-FOSSA$/sysvol'
[DEBUG] * Creating directory...
[DEBUG] * The mountpoint is already mounted.
Hallo.
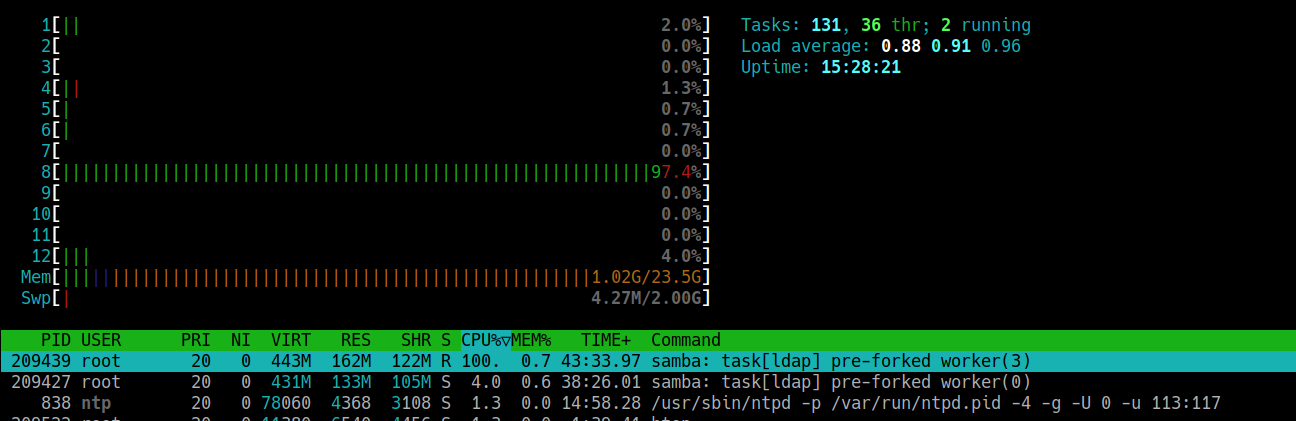
Leider wird’s nicht besser sondern bleibt serverseitig kritisch:
Wenn ich den Prozess mit service samba-ad-dc restart neu starte, ist der Prozess samba: task[ldap] pre-forked worker in sehr kurzer Zeit wieder auf 100% CPU Last. Und das auch ganz ohne Anmeldung von außen.
Ich gehe im Moment von einem Serverproblem aus. Daher die Frage: Kann mir jemand eine /etc/samba/smb.conf zum Vergleich schicken? Dann könnte ich das schon mal vergleichen. So ist leider keine Anmeldung mit einer ganzen Klassen möglich.
Ich hatte ein mal das gleiche Problem, es lag an einer hängende externe App, die 1000 Ldap Requests/s an den Server geschickt hat.
Beim Durchlesen in den Serverlogs ist es mir aufgefallen. Genauso war der Last auf dem Server hoch, und die Anbindungen sehr langsam.
Nach Restart von der externen App, war alles wieder ok.
Also, an deiner Stelle würde ich die Logs auf dem Server anschauen.
und danach unter /var/log/samba/log.*mitgelesen. Dabei fiel mir auf, dass es natürlich viele LDAP-Anfragen von folgenden Servern gibt:
MDM (relution)
mail-Server (mailcow-dockerized)
Nextcloud (ldap-Anbindung und steigende Tendenz die Nextcloud-App zu verwenden)
Das ist aber alles nicht neu, sondern läuft so schon länger. Nun habe ich bereits alle drei Maschinen neu gestartet – aber der Effekt bleibt trotzdem bestehen.
Seltsamerweise geht die Last aber im Moment immer mal wieder auch wieder runter auf ein normales Maß … aber ein paar Sekunden später ist sie wieder bei 100%. Ich habe es währenddessen mit einer ganz normalen moodle-Anmeldung über LDAP auf Port 636 versucht: Das funktioniert sofort und völlig problemlos.
Aber es war heute Morgen im Computerraum wirklich extrem nervig, da sich mindestens die Hälfte der Clients nicht anmelden konnte. Die nichtssagende Fehlermeldung auf den Ubuntu-Clients hat nicht weitergeholfen – am Ende war die Stunde halb um, ohne dass fachlich großartig etwas gelaufen wäre … angemeldet waren dann aber immernoch nicht alle. Das Verhalten liegt reproduzierbar an dem hängenden Prozess, denn wenn ich den Samba-Service neu starte, gehen einige Anmeldungen sofort durch bevor die CPU-Last wieder hochfährt.
Wie kann ich noch genauer eingrenzen, was diese Last verursacht?
Danke nochmal.
Michael
In der Log-Datei [root@server:/var/log/samba]$ tail -f log.samba
tauchen sehr oft Einträge dieser Art auf…
[2023/09/28 08:20:24.071732, 2]
../../auth/auth_log.c:647(log_authentication_event_human_readable)
Auth: [Kerberos KDC,ENC-TS Pre-authentication]
user [(null)]\[RAUM2-PC30$@LINUX.MEINE-SCHULE.DE] at
[Thu, 28 Sep 2023 08:20:24.071711 CEST] with [aes256-cts-hmac-sha1-96] status
[NT_STATUS_WRONG_PASSWORD]
workstation [(null)]
remote host [ipv4:10.20.200.30:42963] mapped to [LINUX]\[RAUM2-PC30$].
local host [NULL]
Diese IP-Adresse kommt aus dem Computerraum – da versucht sich also offenbar gerade jemand erfolglos anzumelden. Ok – Schüler geben schon mal ihr Passwort falsch ein aber SO oft, wie der Eintrag in der Log-Datei auftaucht, kann das nicht sein!
Da stimmt etwas grundsätzliches nicht … es ist übrigens nicht so, dass die Einträge immer so lauten. Ab und zu ist dann auch eine Meldung dabei: Auth: [Kerberos KDC,ENC-TS Pre-authentication] ... [NT_STATUS_OK]
Für mich sieht das alles nach einem Timeout aus: Da die CPU-Last des Prozesses so hoch ist, steigt die Kerberos-Auth irgendwann aus!??
Was steht bei Euch in der Datei /etc/samba/smb.conf unter ntlm auth??
Ich habe dort 2020 diesen Eintrag gemacht: ntlm auth = mschapv2-and-ntlmv2-only
Ist das richtig?
… ich warte noch immer auf eine Antwort auf meine Fragen.
Wurde der Client aktualisiert? Welcher Client ist auf den ubunturechnern
den installiert?
Wurde ein linuxmuster-import-devices gemacht?
Seltsame „manchmal geht es manchmal nicht“ Probleme bei der Anmeldung
sind meist auf falsche Systemzeiten zurück zu führen.
Man muss sie auf OPNSense, Server und (betroffenen)Client überprüfen.
Hallo Holger,
auf Deine Fragen hatte ich oben in #5 bereits geantwortet
(OT: Liest Du die Beiträge hier alle weiterhin per eMail? Dann kommen nachträglich Änderungen an den Beiträgen nicht auch nachträglich per eMail an, oder??)
Hast du den mal die Defaultgpos erstellt?
Das würde ich als nächstes nochmal probieren. Die Zeiten sind synchron. Es ist ja auf dem Server auch eindeutig auszumachen, dass die CPU-Last das Problem verursacht. Wenn ich Samba neu starte, flutscht die Anmeldung sofort durch (bevor es ein paar Sekunden später wieder hoch auf 100% geht).
Hallo. @liv_uo Ja, das dachte ich mir … ich lese die Beiträge schon seit Ewigkeiten direkt im Browser bzw unterwegs in der App …
aber zurück zur Sache: @arnaud: In der syslog und im auth.log steht nichts brauchbares
Gerade habe ich eine VM mit jammy gestartet. Systemzeiten stimmen überein.
Anmeldung lief völlig problemlos und es sind auch alle Netzwerklaufwerke vorhanden. Aber ich habe es in dem Moment auch alleine und nicht mit einer ganzen Klasse ausprobiert. CPU-Last ist im Moment wieder bei 0.
… und kaum habe ich den Satz zu Ende geschrieben, geht’s wieder hoch auf 100%
… ich habe mir die drei Kandidaten, die per LDAP auf den Server zugreifen, nochmal systematisch vorgenommen:
Zunächst habe ich das MDM (relution, docker-Container) heruntergefahren - keine Änderung.
Dann habe ich den mailcow-docker-Container heruntergefahren und siehe da: Die CPU-Last des Prozesses geht runter und bleibt auch unten. Damit ist zwar der Verursacher gefunden – nicht aber der Grund, warum das „plötzlich“ so viel Last auf dem Server erzeugt?!
… und noch etwas genauer: Ich habe auf dem mailcow-Server den Container netzint/linuxmuster-mailcow angehalten.
In diesem Container läuft das Script python3 syncer.py, das dafür sorgt, dass die Logins auf dem v7-Server und die Postfächer auf dem mailcow-Server synchron gehalten werden. Offenbar liegt das Verhalten mit der Auslastung der CPU an diesem Container!
Ich habe zwischendurch das Update-Script vom mailcow-Container laufen lassen, aber an dem zusätzlichen linuxmuster-mailcow-Container habe ich seit Monaten nichts geändert.
Fest steht aber: Seitdem der Container gestoppt wurde, ist auch die CPU-Last für diesen Prozess wieder unten. Sehe ich das richtig: Solange sich an den Server-Logins nicht ändert, muss auch der netzint-Container nicht zwingend laufen? Ich würde gerne die Anmeldung in einem Computerraum nochmal testen, um beurteilen zu können, ob sich wieder alle User gleichzeitig anmelden können.
… war da nicht irgend ein Problem mit dem mailcontainer und den
Schuladmins (oder irgendwelchen Nutzern) deren Mailquoty zuklein/nicht
vorhanden war und deswegen gab es da Probleme?
Hallo Holger –
das kann schon sein, aber mit dem Update-Befehl (./update.sh) werden doch alle Container angehalten und auf den aktuellen Stand gebracht – darunter also auch der angehängte Container image: netzint/linuxmuster-mailcow
Von daher sollte ich auf dem aktuellen Stand sein !?
Du beziehst Dich sicher auf diesen Thread, richtig? →
Eine Lösung für das Problem sehe ich leider weiterhin nicht – außer, dass der Container im Moment nicht läuft.