Hi.
Heute war es dann soweit … wir virtualisieren mit Proxmox und haben das ganze so angelegt, dass alle VMs auf einem RAID-10 liegen und die Systemplatte auf einer einzelnen HDD liegt. Die Vor- und Nachteile dieser Installation wurden hier ja schon öfter diskutiert.
Heute hat jedoch ein großer Nachteil zugeschlagen: Die Systemplatte hatte plötzlich read/write Fehler und scheint sich zu verabschieden. Die VMs liefen aber fehlerfrei weiter. Das ganze fiel zunächst also gar nicht auf, sondern nur deshalb, weil z.B. SSH auf den Proxmox-Host plötzlich nicht mehr wollte. Alle Festplattenzugriffe auf die Systempartition konnten schließlich nicht mehr bearbeitet werden, so dass auch die Befehle “qm stop”, “reboot”, “poweroff” usw auf dem Proxmox-Host nichts mehr gebracht haben. Am Ende blieb mir nur ein harter RESET übrig, um die Kiste neu starten zu können. Immerhin habe ich noch per ssh ein paar VMs heruntergefahren, um nicht die Dateisysteme zu zerlegen (denn ssh auf die VMs funktionierte ja weiterhin!)
Ende vom Lied: Der Server kam klaglos wieder hoch und die Meldungen waren weg … dennoch muss da schnell eine andere Systemplatte rein. Das ist kein großes Problem, da wir das System ja einfach klonen können. Dennoch bleibt jetzt die Frage, ob hier jemand Live-Backups bzw eine Hot Copy seines laufenden Systems macht, um jederzeit einfach auf eine parallel mitlaufende zweite Systemplatte ausweichen zu können?! Auf diese Weise wäre die Downtime nur minimal.
wir verwenden bei uns ein RAID 1 aus zwei SD-Karten. Die stecken in einem Controller, der uns per SNMP mitteilt, wenn da eine Karte ausfällt z.B. oder etwas anderes nicht stimmt. Bisher gab es erst 1x ein Problem damit wegen der unzähligen Stromausfälle, die wir bei uns haben
Hi.
Das klingt nach einer Alternative! Welches Modell habt ihr denn da verbaut, dass es SNMP (Version 2?) kann? Da hier sowieso ein MoniPi zur Überwachung läuft, könnte der den gleich mit beobachten…
Soll das wirklich „SD“ heißen oder fehlt da ein „S“?
ja, es sind SD Karten, die in unserem Dell Server in deren “Internal Dual SD Module” laufen. Dell hat für seine Server eine Remote-Interface (gibt es für andere Server sicher auch), darüber können wir dann per SNMP den Status aller Komponenten abfragen oder das BIOS konfigurieren oder … (iDRAC)
Ich vermute aber, dass man das auch per (selbstkonfigurierten) SNMP-Interface bei einem normalen RAID machen kann.
Platten sterben ja selten von jetzt auf gleich. Um mit zu bekommen, wann die Platten sterben, bieten sich aus meiner Sicht die smartmontools an, i.d.R. auch mit Hardware-Raid Controllern. Mit
smartctl -A … können wichtige Parameter der Platten ausgelesen werden:
Reallocated_Sector_Ct
Current_Pending_Sector
Sind diese Werte > 0 und wachsen, stirbt die Platte und sollte ersetzt werden. Mit
smartctl -t long … kann ein Test (Hintergrund) gestartet werden (Ergebnisse mit -a), der die komplette Platte überprüft. Dies kann z.B. über die smartd.conf und den smartd-Deamon ein mal pro Woche erledigt werden. So weiß man immer, wie es den Platten geht. Über z.B. check_mk können diese Werte mit Hilfe des smart - Plugins abgefragt werden.
Um im jetzigen Zustand ein Backup der System Platte zu haben, würde ich sie mit Clonezilla offline auf eine andere Platte 1:1 (sektorbasiert) kopieren und dann ersetzen. Ziel sollte natürlich ein Raid 1 sein …
Geht es um die Werte in der letzten Spalte bei „RAW“? Dann sieht noch alles ok aus und die Ursache muss woanders liegen?!
Wo/wie hast du das installiert? Auf unserem Proxmox wollte ich schon mal das *.deb-Paket (check-mk-raw-1.2.8p17_0.jessie_amd64.deb) zu check_MK installieren, doch das hat alles mögliche mit angezogen (xinetd usw…), so dass ich dann die Finger davon gelassen habe.
Geht es um die Werte in der letzten Spalte bei „RAW“? Dann sieht noch alles ok aus und die Ursache muss woanders liegen?!
In den Spalten Value (jetzt), Worst (schlimmster) und Threshold (Schwelle zu failed) hast du normalisierte Werte. Die RAW-Werte sind nicht normalisiert. Beispiel:
Ich verstehe diese Zeile so: Die Platte wwar 41418h in Betrieb. Es sind noch 44% der zu erwartenden Lebenszeit übrig. Dies ist gleichzeitig der schlechteste bisher gemessene Wert. Die Schwelle zum erwarteten Tot liegt bei 0%.
Geht es um die Werte in der letzten Spalte bei „RAW“? Dann sieht noch alles ok aus und die Ursache muss woanders liegen?!
Ja. Sieht erst einmal OK aus. Wenn ein ein smartctl -t long … ohne Fehler durchläuft und die Werte weiterhin so bleiben, ist die Platte aus meiner Sicht physikalisch in Ordnung. Die Ursache sollte dann woanders liegen. Kaputtes Dateisystem, RAM …
Wo/wie hast du das installiert? Auf unserem Proxmox wollte ich schon mal das *.deb-Paket (check-mk-raw-1.2.8p17_0.jessie_amd64.deb) zu check_MK installieren, doch das hat alles mögliche mit angezogen (xinetd usw…), so dass ich dann die Finger davon gelassen habe.
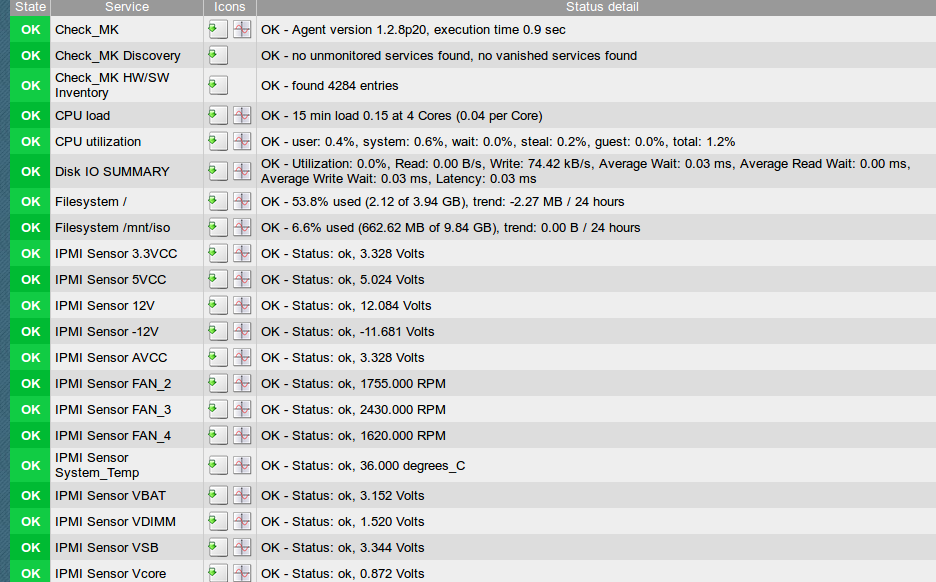
Ja, habe den Agenten installiert, allerdings das rpm-Paket auf Citrix-Xen Servern ;-). Das deb-Paket für Proxmox sollte OK sein, ist ja Debian. Xinetd wird installiert, weil check_mk dann auf Port tcp/6556 lauscht, was über xinetd gestartet wird. Die anderen Pakete werden installiert, um Dinge des Systems abfragen zu können. Des Weiteren installiere ich immer noch das ipmi und/oder das lm-sensors Paket, um die Hardware-Sensoren des Rechners/Servers abfragen zu können. Folgend dann die Plugins unter /usr/lib/check_mk_agent/plugins:
(lmsensors)
mk_inventory.linux
smart
Auch werden, falls es einen RAID-Controller gibt, die Tools des Controllers benötigt. Bei LSI z.B. MegaCli64 …
OK, zunächst haben wir das SATA-Kabel gegen ein hochwertiges Exemplar getauscht. Es läuft alles wieder. Jetzt, wo ich die smartctl-Befehle nutze, lässt sich das ja wunderbar beobachten.
Das Paket IPMI macht nur Sinn, wenn der Server eine entsprechende Karte an Bord hat, oder wie muss ich das verstehen? Ich schaue mir die Installation unter Proxmox auf jeden Fall nochmal an. Eine Sache ist bei uns übrigens noch ungelöst: wie habt ihr die Desaster-(eMail)-Benachrichtigung im MoniPi umgesetzt? Ich habe gelesen, dass der Weg via EMail nicht als optimal eingestuft wird: https://mathias-kettner.de/cms_notifications.html
unter Punkt 9
Wir verwenden für unsere Benachrichtigungen Slack (ich weiß, Mattermost oder RocketChat wären die freien Alternativen, aber ich hatte zum damaligen Zeitpunkt nicht die Zeit und die strukturellen Voraussetzungen zum einzurichten…). Da haben wir einen Channel für das Monitoring und ein entsprechendes Plugin für check_mk. So kommen die Nachrichten in fast jedem Fall sofort an (so lange man redundantes Internet hat…). Wir nutzen Slack auch für Notifications für unseren Helpdesk (Osticket) oder Projektmanagement (Trello).
Das Paket IPMI macht nur Sinn, wenn der Server eine entsprechende Karte an Bord hat, oder wie muss ich das verstehen?
Viele Servermainboards haben ipmi bereits onboard. Würde einfach das Packet ipmitool installieren, eventuell notwendige Module laden und mir die Ausgabe von ipmitool sensor anschauen. Falls da was kommt, kann es check_mk verarbeiten. Ansonsten das Paket lm-sensors verwenden und mit sensors-detect und sensors schauen, was da so ausgelesen werden kann.
Eine Sache ist bei uns übrigens noch ungelöst: wie habt ihr die Desaster-(eMail)-Benachrichtigung im MoniPi umgesetzt? Ich habe gelesen, dass der Weg via EMail nicht als optimal eingestuft wird:
Persönlich greife ich lieber selbst mit Hilfe eines Clients auf check_mk zu, also komplett ohne Mails. Unter Windows/OS X/ und Linux mit „Nagstamon“ und unter Android mit aNag.
Das kannte ich noch nicht und ich frage mich auch gerade, wie das mit Subnetting läuft, wenn der Client z.B. Switche in VLAN.2, den Server im grünen Netz und den Proxmox selbst, der wieder in einem anderen Segment läuft, alle zusammen überwachen können soll!?
Bzw ist die Frage dann eher, wie das ein Client von außen (z.B. per OpenVPN) schafft, denn im grünen Servernetz geht es ja!? Die Überwachung per Client läuft dann ja auch nur, solange man auch per VPN eingeloggt bleibt, oder wie machst du das genau?
Das kannte ich noch nicht und ich frage mich auch gerade, wie das mit Subnetting läuft, wenn der Client z.B. Switche in VLAN.2, den Server im grünen Netz und den Proxmox selbst, der wieder in einem anderen Segment läuft, alle zusammen überwachen können soll!?
Der Client fragt nicht die Statusdaten der Geräte, sondern die Statusdaten von Check_mk/Nagios ab. Anstelle mich auf der Weboberfläche einzuloggen, nutzt man also die Infos, die der Client liefert und von check_mk eingesammelt hat.
Bzw ist die Frage dann eher, wie das ein Client von außen (z.B. per OpenVPN) schafft, denn im grünen Servernetz geht es ja!? Die Überwachung per Client läuft dann ja auch nur, solange man auch per VPN eingeloggt bleibt, oder wie machst du das genau?
Wie bereits geschrieben, der Client nutzt die Statusdaten (LiveStatus) von check_mk. Check_MK ist bei mir aus dem Internet erreichbar. Wenn das zu unsicher ist, kann man noch einen „Knock“-Service davor hängen oder nutzt den OpenVPN-Tunnel.
Die Clients nutze ich dann auf meinem Smartphone, meinem PC zu Hause … und bin immer auf dem neusten Stand. Die Statusdaten werden dabei z.B. alle 15 Minuten automatisch eingesammelt.
Nein Wir sind eigentlich eine sehr kleine Schule, aber das schöne an Slack / Mattermost ist, dass man über „Integrations“ viele Dienste darin zusammenlaufen lassen kann. Das war einer der Gründe, warum wir (d.h. wir haben einen 100% IT-Allround-Menschen + 1-2 weitere Leute, die in der IT unterschiedlich stark mit eingebunden sind) Slack nutzen. So ist jeder immer auf dem aktuellen Stand. Allein macht das natürlich nicht so viel Sinn
-- Unit ipmievd.service has begun starting up.
May 28 12:05:18 pve2 systemd[1]: Failed to reset devices.list on /system.slice: Invalid argument
May 28 12:05:18 pve2 ipmievd[30833]: Could not open device at /dev/ipmi0 or /dev/ipmi/0 or /dev/ipmidev/0: No such file or directory
May 28 12:05:18 pve2 systemd[1]: ipmievd.service: control process exited, code=exited status=1
May 28 12:05:18 pve2 systemd[1]: Failed to start IPMI event daemon.
Wir haben aber auch (leider) keinen „waschechten Server“ da stehen sondern alles Marke „Eigenbau“ mit einem Board von Gigabyte Technology Co., Ltd. GA-990FXA-UD5.
Übrigens läuft der Server seit dem Kabeltausch wieder rund. Ich gehe davon aus, dass das die Ursache war…
Hi.
Jetzt weiß ich wieder, warum ich damals die Finger von “check_MK” unter Debian / Jessie gelassen habe:
The following packages have unmet dependencies:
check-mk-raw-1.2.8p23 : Depends: curl but it is not installed
Depends: dialog but it is not installed
Depends: fping but it is not installed
Depends: graphviz but it is not installed
Depends: libapache2-mod-fcgid but it is not installed
Depends: libapache2-mod-proxy-html but it is not installed
Depends: libltdl7 but it is not installed
Depends: libnet-snmp-perl but it is not installed
Depends: libpango1.0-0 but it is not installed
Depends: libsnmp-perl but it is not installed
Depends: binutils but it is not installed
Depends: rpm but it is not installed
Depends: php5 but it is not installed
Depends: php5-cgi but it is not installed
Depends: php5-cli but it is not installed
Depends: php5-gd but it is not installed
Depends: php5-mcrypt but it is not installed
Depends: php5-sqlite but it is not installed
Depends: php-pear but it is not installed
Depends: lcab but it is not installed
Depends: snmp but it is not installed
Depends: xinetd but it is not installed
Depends: python-ldap but it is not installed
Depends: libfreeradius-client2 but it is not installed
Depends: libgsf-1-114 but it is not installed
Depends: python-reportlab but it is not installed
Depends: python-imaging but it is not installed
Depends: poppler-utils but it is not installed
Depends: python-openssl but it is not installed
E: Unmet dependencies. Try using -f.
Ich war nicht sicher, ob das alles problemlos auf einem Proxmox nachinstallierbar ist – natürlich ohne den Proxmox zu stören.
das ist das Installationspaket des Management-Servers!!! Das ist falsch! Es muss das DEB-Paket des Agents installiert werden. Zu finden unter Wato --> Monitoring Agents …

 Um mit zu bekommen, wann die Platten sterben, bieten sich aus meiner Sicht die smartmontools an, i.d.R. auch mit Hardware-Raid Controllern. Mit
Um mit zu bekommen, wann die Platten sterben, bieten sich aus meiner Sicht die smartmontools an, i.d.R. auch mit Hardware-Raid Controllern. Mit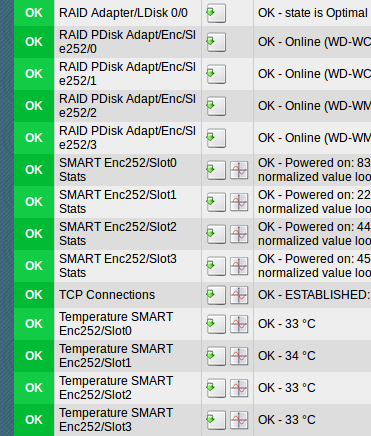
 Das ist falsch! Es muss das DEB-Paket des Agents installiert werden. Zu finden unter Wato --> Monitoring Agents …
Das ist falsch! Es muss das DEB-Paket des Agents installiert werden. Zu finden unter Wato --> Monitoring Agents …