Seit einiger Zeit haben wir auch das Problem, dass das Hochfahren der Rechner und die Anmeldung an den Clients extrem lange dauert. Direkt zu Beginn des Schuljahres nach dem Update auf lmn 7.3 war das noch nicht der Fall.
Gerade eben half offensichtlich ein Neustart von samba-ad-dc.service.
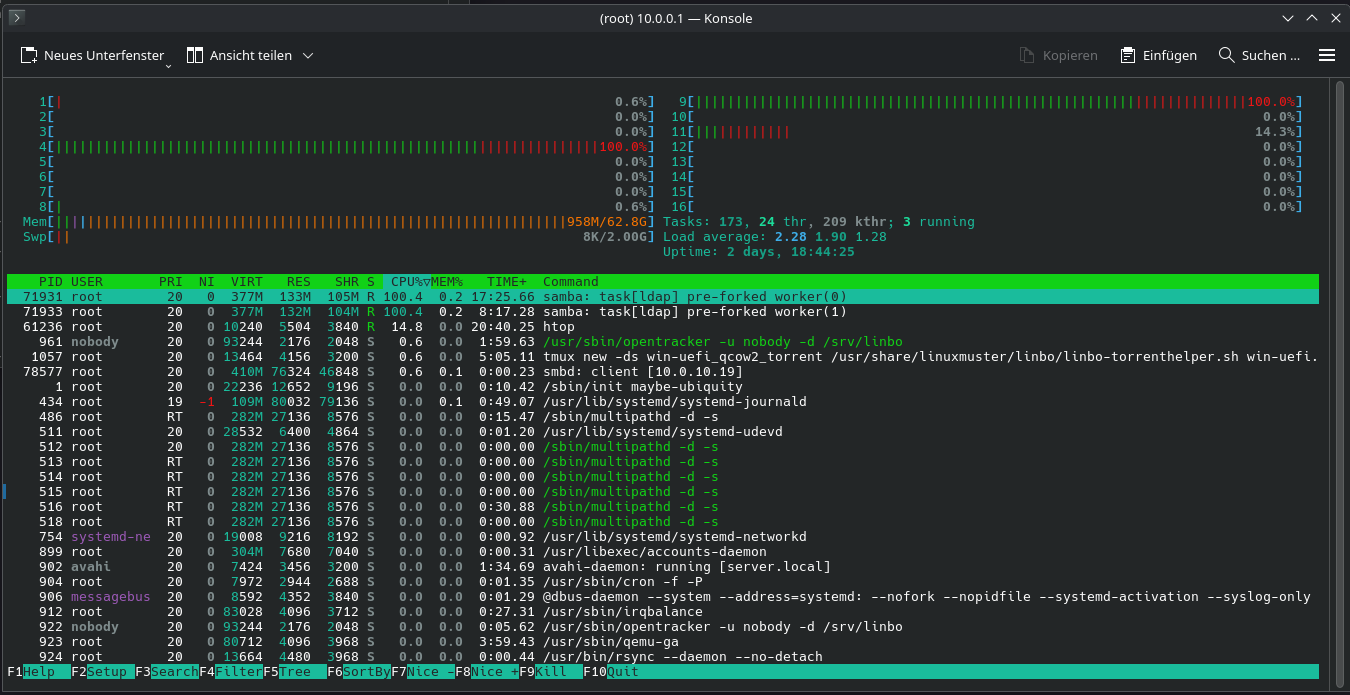
Die VM für den Server hat 16 Kerne. Manchmal liegen zwei davon bei knapp 100%. Die anderen aber tun gar nichts.
Wie kann ich dem Problem auf die Spur kommen? Welche Methoden zur Analyse könnt Ihr mir vorschlagen?
Nicht hundertprozentig. In der htop-Ausgabe stand Samba nicht ganz oben, als die Anmeldung bei meinen Schülern so lange hing. Trotzdem half es, den Dienst neu zu starten.
Zwei Kerne scheinen permanent mit Samba beschäftigt zu sein. Alle anderen Kerne langweilen sich, aber das System reagiert extrem schleppend. Dies betrifft beispielsweise auch die Ladezeit für die Startseite der Schulkonsole. Die DNS-Auflösung funktioniert dann nicht mehr:
$ nslookup server.lmn.ohgw.de
;; communications error to 10.0.0.1#53: timed out
;; communications error to 10.0.0.1#53: timed out
;; communications error to 10.0.0.1#53: timed out
;; no servers could be reached
Ein Neustart des Samba-Dienstes hilft für einen ganz kleinen Moment, wie man hier sieht:
Das finde ich ja fast „beruhigend“, dass wir nicht die einzigen mit diesem Problem sind.
Habt ihr bei Euch VMs im Einsatz , die einen Abgleich der User per LDAP machen?
Als Kandidaten kommen in Frage
Nextcloud
Mailcow
Edulution
…
Es liegt bei uns sehr wahrscheinlich an einer oder mehrerer dieser VMs, die regelmäßig per LDAP alle User abgleichen. Bei Mailcow habe ich die Zeiten zwischen den Checks beispielsweise bereits hoch gedreht, so dass das nur noch einmal am Tag durchgeführt wird. Kann es das bei Dir auch sein??
Könnte es sein, dass sich auch durch ein Nextcloud-Update etwas geändert hat? Wir haben mittlerweile Version 32.0.0. In den Administrationseinstellungen finde ich nichts über regelmäßige LDAP-Syncs. Könnte dieser Parameter etwas damit zu tun haben?
liefert bei uns keine Ausgabe. Der Wert ist also anscheinend nicht gesetzt. In der Nextcloud-Doku findet sich ein Beispiel mit einem Intervall von einem Tag. Wenn man die Zeit nicht vorgeben kann, könnte das ja aber auch mitten während des Unterrichts zuschlagen.
Kann jemand sagen, was ich bei unseren Nextcloud-Instanzen überprüfen bzw. setzen sollte?
vielleicht habt ihr aber auch nur mal ein neues Image gemacht, und jetzt ist das Vorlagenprofil größer und deswegen dauert der Login länger.
Oder es ist der Wurm im Netzwerk: ein Switch stirbt und macht Fehler in Masse auf dem Uplinkport zum Backbone …
… nur so ein paar Gedanken
LG
Holger
Hallo Holger, nein, das kann ich deshalb ausschließen, weil die CPU Last auf dem v7 Server verschwindet, sobald ich die Mailcow-VM beende. Starte ich die VM neu, kommt früher oder später auch der Samba-Prozess mit der hohen CPU-Last zurück.
(Schaut mal nach python3 syncer.py)
Zu Nextcloud kann ich diesbezüglich nichts sagen aber bei Mailcow sieht das ziemlich eindeutig aus
Viele Grüße
Michael
tatsächlich ist das Vorlagenprofil in Windows bei uns etwas aus dem Ruder gelaufen. Das betrifft ja aber nur die erstmalige Anmeldung eines Benutzers an einem Rechner. In meinen Klassen und Kursen gibt es eine feste Sitzordnung, so dass ich sicher sein kann, dass nicht jedesmal ein neues Profil erzeugt wird.
An die Switche komme ich nicht selbst heran. Der Schulträger hat aber keinen Hinweis darauf gefunden, dass im Netz etwas im Argen ist.
Das Problem äußert sich schon beim Booten von Linbo, wobei ja auch schon Zugriffe auf den AD/DC-Server erfolgen.
Ich habe also wirklich die jüngsten Nextcloud-Updates und unsere neue Mailcow-Anbindung im Verdacht.
Ich verstehe aber nicht, warum Samba sich nur zwei bis drei Kerne greift und warum der ganze Server, also auch die Web-UI lahmt, wenn noch so viele CPU-Ressourcen frei sind.
Würde eine Umstellung auf Keycloak für die externen Dienste helfen? Das wäre ein dickes Brett, aber eigentlich habe ich ohnehin vor, mittelfristig eine SSO-Lösung zu etablieren.
Hallo.
Ich habe gerade mal ChatGPT um Rat gebeten und das Script vom Mailserver unter /opt/linuxmuster-mailcow/src/syncer.py zur Analyse hochgeladen. Dieses Script verursacht hier offenbar die häufige CPU-Last, die den Samba-Server so stark belastet.
Leider bin ich in Python nicht fit genug, um die Optimierungsvorschläge richtig einschätzen zu können. Mein verwendeter Prompt war denkbar einfach:
Kannst Du dieses Python-Script untersuchen?
und nach der ersten ausführlichen Analyse dann die etwas ungenaue Anfrage (die aber erstaunlich präzise Antworten liefert):
Kann es sein, dass dieses Script einen Samba-Server so stark belastet, dass die CPU-Last sehr oft auf 100% hoch geht?
Als Kurzzusammenfassung liefert ChatGPT das hier:
| Ursache | Auswirkung | Lösung |
| ---------------------------- | ------------------------------------- | ------------------------------- |
| Endlosschleife mit 30s Sleep | Dauer-Queries auf LDAP | Intervall erhöhen |
| Kein Delta-Sync | Volle Directory-Abfragen | Filter nach `whenChanged` |
| Kein Paging | Samba muss große Antworten generieren | `paged_search` aktivieren |
| Wiederholte Binds | CPU-Overhead durch Authentifizierung | Persistente Verbindung |
| Keine Indexe | Suchanfragen dauern lange | Indexierung in Samba aktivieren |
Vielleicht kann jemand das Problem damit genauer unter die Lupe nehmen?
Viele Grüße,
Michael
wir haben die Samba-Probleme noch immer. Da DNS-Anfragen oft in einen Timeout laufen, können wir kaum noch sinnvoll arbeiten.
Folgende Versuche haben leider nichts gebracht:
LDAP-Synchronisationsintervall im extern gehosteten Mailcow auf 12 Stunden einstellen
alle Switche (vom Schulträger) neu starten lassen
Unser lmn Server (AD/DC-Controller) hat 16 vCPU und 64 GiB RAM. Das sollte eigentlich mehr als ausreichend sein. Die gesamte CPU-Last übersteigt laut Proxmox auch im Maximum nie den Wert von 30%. Mittels htop sieht man aber, dass der Samba-Prozess die meiste CPU-Zeit frisst.
Wie kann ich am besten eine aussagekräftige Statistik darüber erstellen, woher die LDAP-Anfragen kommen. Direkt auf dem Server? Oder auf der OPNsense? Ein journalctl -f für den Samba-Dienst liefert mit dem Standardeinstellungen keine aufschlussreichen Einträge.
Wir müssen dringend herausfinden, welches der externen Systeme für die Hauptlast verantwortlich ist:
Nextcloud für Lehrer und Schüler (extern)
Nextcloud für Lehrer (intern in der DMZ)
Moodle für Lehrer und Schüler (extern)
Mailcow für Schüler (extern)
WebUntis für Lehrer und Schüler (extern)
MediaWiki für Lehrer (intern)
Gitea für Lehrer und Schüler (intern)
Kann mir jemand sagen, wie ich die Zugriffe am besten protokolliere?
nein, wir stellen Home_auf_Server nicht in den Nextcloud-Instanzen bereit. In den Computerräumen greifen wir nur über das Web-Interface zu. Zu Hause und auf dienstlichen Notebooks haben manche den Nextcloud-Client.
Hallo Matthias,
benutze auf dem v7-Server mal die beiden Befehle iftop und nethogs. Dann siehst Du, wohin der Traffic über Port 636 geht.
Wenn Du dann die verdächtige VM kennst, kannst Du sie ja mal für eine gewisse Zeit herunterfahren, um zu schauen, ob die CPU-Last auf dem Samba-AD danach verschwunden ist.
DNS Probleme können sich immer auf die unterschiedlichsten Weisen manifestieren. Ich rate dazu das sauber ein zu stellen.
Die „Grünen Haken“ bei der Kerberos auth in der OPNsense sind da ein guter HInweis.
Sind sie alle Grün, dann ist das mit dem DNS in der OPNsense wahrscheinlich richtig konfiguriert.
Wenn nicht, dann würde ich da mal hinschauen.
LG
Holger
ich habe die Kerberos-Seite in der OPNsense gerade nochmal überprüft. Alle Haken sind grün, und die Test-Authentifizierung klappt. Nach dem Update von lmn 7.2 auf 7.3 habe ich das aber nur mit Deinen DNS-Einstellungen hinbekommen, nicht mit denen in der Doku.
Mittels iftop sehe ich keinen ungewöhnlich starken Datenverkehr auf Port 636. Die IT-Abteilung der Stadt bestätigt dies auf der Firewall für das gesamte Schulzentrum.
Im Journal finde ich folgende Auffälligkeit:
Nov 05 15:55:31 server.lmn.ohgw.de dhcpd[946]: DHCPREQUEST for 10.0.0.x from ff:ff:ff:ff:ff:ff (OHG-XX-XX) via eth0
Nov 05 15:55:31 server.lmn.ohgw.de dhcpd[946]: DHCPACK on 10.0.0.x ff:ff:ff:ff:ff:ff (OHG-XX-XX) via eth0
Nov 05 15:55:35 server.lmn.ohgw.de dhcpd[946]: execute_statement argv[0] = /usr/lib/linuxmuster/dhcpd-update-samba-dns.py
Nov 05 15:55:35 server.lmn.ohgw.de dhcpd[946]: execute_statement argv[1] = delete
Nov 05 15:55:35 server.lmn.ohgw.de dhcpd[946]: execute_statement argv[2] = 10.63.x.x
Nov 05 15:55:35 server.lmn.ohgw.de dhcpd[946]: data: host_decl_name: not available
Was bedeutet data: host_decl_name: not available?
Ansonsten ist mir vollkommen unklar, warum samba: task[ldap] in htop meist ganz weit oben erscheint.