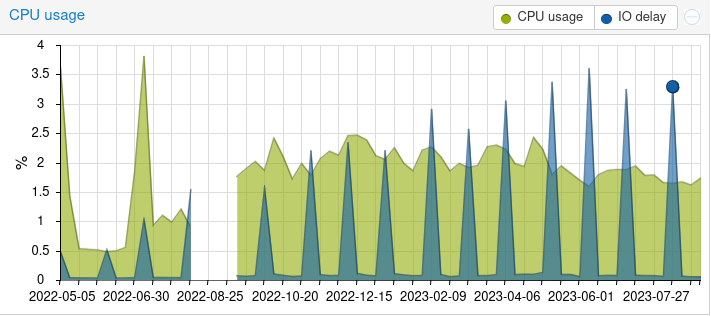
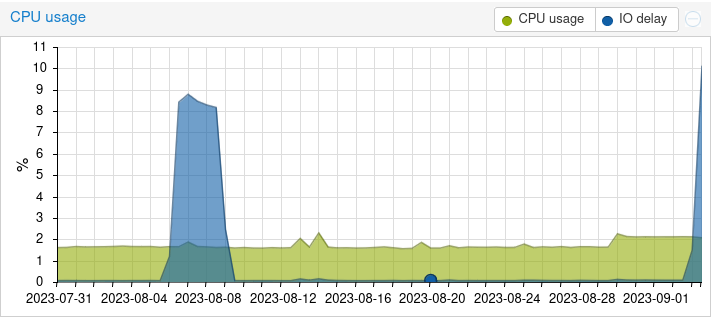
Dass das bei mir so regelmäßig auftaucht ist kein Wunder: Das Debian-Paket „zfsutils-linux“ installiert einfach einen Cronjob, der das regelmäßige manuelle trim auslöst, ebenso scrub.
root@serverhost1:~# cat /etc/cron.d/zfsutils-linux
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
# TRIM the first Sunday of every month.
24 0 1-7 * * root if [ $(date +\%w) -eq 0 ] && [ -x /usr/lib/zfs-linux/trim ]; then /usr/lib/zfs-linux/trim; fi
# Scrub the second Sunday of every month.
24 0 8-14 * * root if [ $(date +\%w) -eq 0 ] && [ -x /usr/lib/zfs-linux/scrub ]; then /usr/lib/zfs-linux/scrub; fi
testweise habe ich bei einer 2TB NVME jetzt „trim“ manuell angestoßen: time zpool trim -w rpool nvme-eui.0024cf015400754f-part3 diese braucht bereits 28 Stunden und erhöht meinen Server-load dabei auf 7,5, den IO-Delay (was auch immer das Maß hier ist) auf 10%.
Aus dem letzten Post sieht man, dass bei vier 2TB platten gleichzeitig sich das trimming auf ca. 3 Tage erhöht bei einem Load von 10-12
Ich stelle fest, dass autotrim bei mir doch nicht angeschalten ist.
zpool get autotrim <poolname>
Mein Fazit: Ich schalte jetzt nach weiteren Tests „autotrim“ an und schalte das manuelle Trimming per Cronjob wieder ab. Dann kann ich in den nächsten Ferien schauen, ob ein manuelles trimming wieder so lange dauert.
Falls ihr weitere Einsicht habt, gerne mit uns teilen.
Hi Tobias,
mein M.2 NVME-Server (6x1TB Riegel) braucht auch so lange und zwar jeder Riegel für sich. Der Server von TK (nicht von Dir schafft das in 20 Minuten, ebenfalls 6x1TB SSD, aber halt Platten, keine Riegel. Ich hab schon Firmware-Upgrades und so probiert (habs nur für einen Typ bekommen), nix beschleunigt das. Mein Server, die Firewall und NC laufen jetzt eben auf dem zuverlässigen Server, der Rest auf dem „langsamen“. Man kann ja aber auch beide Trim-Möglichkeiten abstellen und in den Ferien von Hand trimmen. Ok, Würgaround, aber besser als nix. Kein Plan, warum das so lange dauert, das Internet hat nix hergegeben.
Mein Experiment, dass nach einem manuellen Trim sofort ein gleiches manuelles trim eigentlich erheblich weniger Zeit brauchen müsste, hat auch nicht geklappt:
erster Durchlauf 28 Stunden, den zweiten habe ich nach ca. 19 Std. abgebrochen. Das macht doch überhaupt keinen Sinn. In dieser Zeit ist doch niemals so viel gelöscht worden.
ich kann mir daher nur vorstellen, dass das trim unnötige Löschaktionen vornimmt oder sogar selbst herstellt (also: nach einem trim ist die M2 in einem Zustand, dass sie ein trim braucht, also wie mit Ferien bei Schülern und Lehrern)
Danach habe ich autotrim=on eingestellt. Dadurch wurde mein Server wieder langsam, wie beim manuellen trim. auch das macht für mich keinen Sinn…
Hach, ich gebs hiermit auch erstmal auf.
Und ja, lieber Stephan Rachel, es heißt „ergibt keinen Sinn“. Grüße!
Hi. Nächste Frage, es sind ein paar Jahre ins Land gegangen.
NVME auf dem Server haben gute Dienste geleistet, keine bislang ausgefallen.
In Proxmox 7.4 sehe ich jetzt auf allen 5 Platten ähnliche Werte, wie das:
SMART/Health Information (NVMe Log 0x02)
Critical Warning: 0x00
Temperature: 58 Celsius
Available Spare: 100%
Available Spare Threshold: 5%
Percentage Used: 4%
Data Units Read: 24,697,505 [12.6 TB]
Data Units Written: 143,433,484 [73.4 TB]
Host Read Commands: 1,197,986,108
Host Write Commands: 3,866,229,013
Controller Busy Time: 22,332
Power Cycles: 15
Power On Hours: 20,996
Unsafe Shutdowns: 5
Media and Data Integrity Errors: 0
Error Information Log Entries: 35
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
Sind die 4% „Percentage Used“ bedenklich? Sind das 4% von den 100% available spare?
Warum ist da ein Threshold von 5% ? Wäre ein Erreichen dieses Threshold ein Marker für eine kaputt gehende NVME?
Zu den Spare-Werten: Die stehen nicht im Zusammenhang mit den 4%. Du hast noch 100% der Ausfallreserve (=spare) zur Verfügung. Der Threshold ist in der Regel der Schwellwert für Warnungen und wenn der aktuell bei 5% noch freier Ausfallreserve liegt, hast du noch 95% bis du dir Sorgen machen solltest.