Habe das Thema hier nicht gefunden.
Dann habe ich habe mal DeepSeek gefragt, und hier seine Antwort:
[…]
Ja, es gibt mehrere KI-Systeme, die für den Einsatz in Bildungsumgebungen besonders geeignet sind – je nach Anforderungen an Datenschutz, Kosten, Technik und pädagogischem Mehrwert. Hier eine Übersicht:
Vorteile: Spezialisiert auf strukturierte Daten und Faktenwissen, weniger Halluzinationen.
Nachteile: Weniger kreativ im Vergleich zu anderen Modellen.
2. Kommerzielle APIs mit Bildungsfokus
Claude 3 (Anthropic)
Vorteile: Starke Ethik- und Sicherheitsfilter, transparente Antworten.
Nachteile: Cloud-basiert (Daten verlassen möglicherweise die EU).
Google Gemini Education
Vorteile: Integration mit Google Classroom, automatische Zitathinweise, DSGVO-konforme Verträge.
Nachteile: Abhängigkeit von Google-Infrastruktur.
Microsoft Azure OpenAI + Copilot
Vorteile: Kombiniert GPT-4-Turbo mit Microsofts Bildungs-Tools (Teams, Office).
Nachteile: Kostenintensiv bei hohem Nutzungsaufkommen.
3. Spezialisierte Bildungslösungen
Khanmigo (Khan Academy)
Vorteile: Didaktisch optimiert für Mathe/Naturwissenschaften, interaktive Tutor-Funktionen.
Nachteile: Bislang nur auf Englisch verfügbar.
Alelo
Vorteile: KI-gestützte Sprachlern-Tools mit pädagogischen Metriken.
Nachteile: Fokus auf Sprachunterricht, weniger Allgemeinwissen.
Cognii
Vorteile: Automatisiertes Feedback für Aufsätze/Essays, adaptiv an Lehrpläne anpassbar.
4. Nischenlösungen für Schulen
Adaptive Lernplattformen:
DreamBox (Mathe) oder Century Tech – KI passt Aufgaben individuell an Schüler:innen an.
Open-Source-Edge-KI:
Raspberry Pi-basierte Mini-Server mit TinyML-Modellen (z. B. BERT-Tiny) für datensparsame Anwendungen.
Sprachassistenten:
MyCroft (Open Source) oder Alexa for Education – für barrierefreie Bedienung.
Entscheidungshilfe: Welches System passt?
Kriterium
Empfehlung
Maximaler Datenschutz
Llama 3/Mistral (On-Premises)
Kostenoptimiert
Open-Source-Modelle + Selbsthosting
Plug-and-Play
Google Gemini Education oder Microsoft Copilot
Fach-Spezialisierung
Khanmigo (STEM) oder Cognii (Schreibfähigkeiten)
Wichtige Schritte zur Umsetzung
Datenhoheit klären: On-Premises vs. Cloud.
Content-Filter testen: Blockieren von unangemessenen/ungesicherten Inhalten.
Kostenmodell vergleichen: API-Gebühren vs. Hardware-Investitionen.
Pilotphase starten: Testen mit einer Klasse, Feedback sammeln.
Tools wie Llama 3 oder Mistral sind ideal, wenn Sie maximale Kontrolle über Daten und Anpassung wünschen – aber technisches Know-how voraussetzen. Für „fertige“ Lösungen lohnt sich der Blick auf Gemini Education oder Microsofts Bildungs-KI.
Haben Sie bereits eine Präferenz für bestimmte Funktionen (z. B. Sprachunterstützung, Mathe-Tutoring)?
Morgen,
ich werde das Gefuehl nicht los, dass die ganzen kostenlosen „on-premise“-Loesungen (Begriff musste wohl erfunden werden, da der Trend zur Cloud geht) eigentlich nur Enttaeuschungen bereithalten, lass mich da aber gerne eines Besseren belehren. Meine Versuche mit selbsgehostetem Llama verbuche ich als gescheitert, ich versteh aber noch nichtmal woher da die Daten kommen bzw. kommen koennen. Die KI selbst bringt ja ohne Trainingsdaten nix, die Daten sind die Kronjuwelen und das was ich bei Llama eingepflegt habe ist Schrott.
Ich vermute (!), dass auch die Hauptmagie in den Subsystemen liegt, die nicht freigegeben werden, sprich die Geschmeidigkeit mit der ChatGPT, Claude und Konsorten zu bedienen sind, gibt’s nicht fuer umme, maximal die dahinterliegende KI.
Wenn ich falsch liege, dann macht mir das diesmal eine grosse Freude, her mit den Infos.
Zum Thema lokale Modelle bezogen auf die aktuell gehypte generative KI:
Die Intelligenz in „generativer KI“ ist nicht intelligent, sondern erscheint nur so täuschend echt. In Wahrheit ist es ein Automat, der anhand des KI-Trainings mit sehr hoher Wahrscheinlichkeit sagen kann, welche Buchstaben bzw. Worte auf die vorigen Buchstaben bzw. Worte folgen. Es ist letztlich „alles nur Statistik“. Daraus ergibt sich dann auch, dass ein KI-Modell mit 7 Milliarden Parametern bessere Antworten liefert als eins mit nur 3 Milliarden Parametern, einfach weil es auf mehr Trainingsdaten zurückgreifen kann. Ollama Search gibt eine Übersicht, welche Modelle sich wofür eignen, da die Anbieter natürlich auch auf Ziele hintrainiert haben. Dort siehst du auf der Detailseite zu jedem Modell, dass es Destillate gibt, d.h. das große Sprachmodell wurde genommen und in der Größe (Speicherverbrauch in Gigabyte) beschnitten, was auch bedeutet, dass die Destillate weniger genau sind als die größte Version. Nun gilt es für sich das Modell mit der kleinsten Größe, den erträglichen Antwortzeiten und noch akzeptablen Antworten zu finden.
Meine Tests mit Ollama auf nicht ganz aktuellem Gaming-PC zeigten z.B., sobald das Modell nicht mehr vollständig in den VRAM der Grafikkarte passte (bei mit 8 GB), stiegen die Antwortzeiten um das zehnfache. Wenn ich damit leben konnte, dann konnte ich dafür wiederum ein Modell bis 60 GB Größe in den RAM laden (macht Ollama automatisch, wenn der VRAM zu klein ist) und bessere Antworten erhalten.
Auf https://open.hpi.de/ gibt es in der Rubrik „Big Data and AI“ etliche Kurse auf Einsteigerniveau.
die originalfrage sollte man wohl so beantworten: „Hängt davon ab“.
Danke an @Buster für die beispielhafte Antwort, wenn man Ollama mit 8GB Grafikkarte nutzt. Ebenso für Knoppers Folien (woraus sich auch „ollama“ als Antwort ergibt).
Danke an @irrlicht , der auch seine Experimente mit Llama als Rückschlag bewertet.
Ich würde die Frage neu formulieren, weil ich „Datenschutz“ gerne so priorisieren würde, dass „google gemini education“ et. al. schon gar nicht auftauchen kann.
Zudem hängt es wohl wirklich davon ab, was du machen willst. Was soll das KI-System leisten (eine Auswahl: Schülerarbeiten einscannen und korrigieren, Bilder generieren, Persona-Chats simulieren, Informatik-Code generieren, Matheaufgaben binnendifferenziert erstellen)
Wir haben hier fobizz abonniert und bislang geht mir das ganz hinten vorbei, aber wenn ich mich mit eigener KI und deren Leistung befassen möchte, dann hab ich wenigstens was zum Vergleichen.
Ich bin noch nicht schlauer geworden, ob es sich überhaupt lohnt, selbst mit dem hosting anzufangen, wenn man a.) einen Raspberry oder b.) einen 5000€-Rechner zur Verfügung/Bestellung hat. Dazu Links mit einfacher Websuche gefunden:
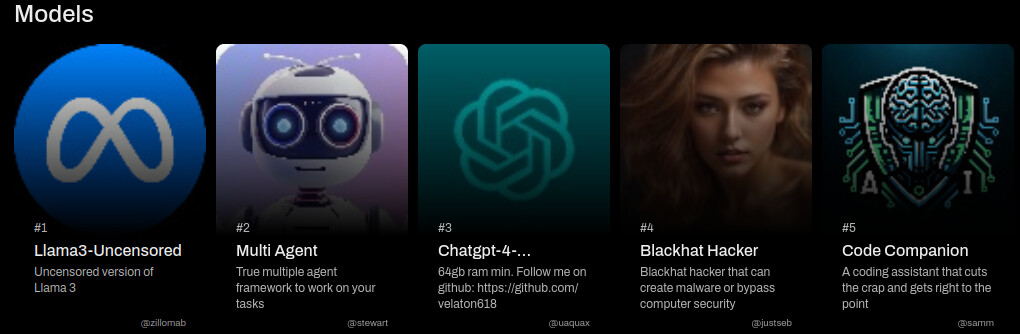
nach etwas mehr Recherche auf ollama oder https://openwebui.com/models?category=education wird mir schlecht, aber klar, was hatte ich erwartet? Die TOP 5 in der Kategorie „Education“: zwei mal „uncensored“ (baut dir Bomben), einmal „Blackhat Hacker“ (erstellt dir malware)
Ich sehe bei generellen Modellen wirklich Schwierigkeiten, das zu verantworten, oder eben erst ab 16?
Bei „coding“-Modellen oder expliziten Sprachassistenten oder ähnlichem sehe ich noch Möglichkeiten, dass es inhaltlich begrenzt wird und jail-breaks die Ausnahme bleiben.
Und selbst dann - going down the rabbithole -
die ethische Dimension des Urheberrechts der Trainingsdaten
Halluzinationen
zensur, die man nicht will, wie deepseek + Tianmen
Bias der Antworten durch Bias in Trainingsdaten
…
Boah, echt kein Bock drauf. Ich warte drauf, dass ich eine Gefährdungsbeurteilung schreiben muss und Eltern mir eine Einverständniserklärung geben müssen, das uns aus der Haftung nimmt, wenn das Kind psychischen Schaden nimmt…
Da ich mich seit einigen Monaten recht intensiv mit dem Thema beschäftigte, ein wenig Senf von mir:
wir haben einen eigenen KI-Server, der nur durch das Zusammenspiel von Förderverein und eines sehr hilfsbereiten Menschen (der uns seine und eine weitere private Grafikkarte auf Rechnung verkauft hat) zustande kam. Zum Testen und Kennenlernen einfach eine nette Sache.
die Programmierung mit Python ist wirklich nett - damit lässt sich auf Anhieb eine Menge basteln (z.B. das Persona-Projekt, das wir für einen Tag der offenen Tür entwickelt haben und mit dem die KI in die Rolle verschiedener historischer Persönlichkeiten schlüpfen kann)
wir haben testweise unser Moodle damit verbunden - das ging auf Anhieb.
ich habe (vor allem als Übung) ein Moodle-Plugin geschrieben, das Freitext-Aufgaben korrigiert. Das ist noch nicht fertig, aber nett: mit Hilfe eines Korrektur-Plugins bekommen die Schülerinnen und Schüler bei einer Freitext-Aufgabe eine auf Rechtschreibung korrigierte Variante ihres Textes und zusätzlich passende Merksätze zurück. Damit werden tatsächlich vollständig korrigierte Klassenarbeiten in allen Anforderungsbereichen möglich, die Lehrkräfte, die das hier mit testen, sind begeistert…
Und wenn jetzt jemand denkt, ich fänd das alles toll, der kann sich z.B. das hier durchlesen und weiß dann, warum ich diese KI-Lobhudeleien für eine ziemliche Katastrophe halte. Werkzeug für welche, die es verstanden haben - eventuell. Aber alles andere…
Das ist ja beim Smartphone schon so, dass wir denken, dass wir Kindern das antun sollten, weil wir selbst (mit unserer smartphonelosen Kindheit) da mehr oder weniger gesund reingewachsen sind… Mit KI also das Gleiche nochmal?!
Warum es genau so klingen muss (egal, wie entkoppelt von der Realität), beantwortet dieser Artikel ganz gut.