Hi.
Ich habe hier ein dickes Problem, das ich nicht eingrenzen kann.
Wir haben VLANs und Subnetting aktiviert; und das ganze zusammen mit Proxmox 5.x.
Nun ist es neuerdings so, dass in gewissen VLANs keine IP-Adressen mehr überkommen; aber nicht in allen.
Schließe ich eine VM an das Servernetz an (bei uns VLAN.11) ist alles ok. Der Rechner hat sofort eine IP und alles ist wie gehabt. Mache ich das gleiche in einem anderen VLAN (wobei die DHCP-Adresse in jedem Fall vom linuxmuster-Server kommt), kommt nichts mehr an.
Das wird Montag ein Riesen-Geschrei, da es auch alle Computerräume, das Lehrezimmer usw betrifft. Jede IP, die in einem anderen Netz als dem Servernetz liegt, kommt nicht mehr an. Wo soll ich da suchen?
Wir hatten das Problem neulich schon mal. Da hat der Neustart des L3-Switches seltsamerweise geholfen (wobei mir nicht klar war, warum der überhaupt bei eine Rolle gespielt hat). Daher hatte ich den auch dieses Mal in Verdacht – hat aber nichts gebracht. Auch ein kompletter Neustart des Hypervisors hat natürlich nichts ergeben.
Hat jemand eine gute Idee, wo ich suchen soll? Ist das ein Problem auf dem Hypervisor oder eher auf dem linuxmuster-Server/IPFire?
Der Server ist nie das Problem: auf 10.16.1.1 komme ich – aber natürlich erst, wenn ich auch 'ne IP bekommen habe. Du meinst also, dass das Problem am ehesten auf dem L3-Switch zu suchen ist?
Na ja – was sollte die verstellt haben? Ich kann mir nicht erklären, warum es im servernetz klappt und in den anderen vlans nicht??
Eine Sache war allerdings seltsam: ich hatte die cisco-konfiguration gesichert und wollte sie auf einem anderen switch wieder einspielen. Da hatte ich immer eine fehler der art “copy error” (ohne genauere Infos)
Es ist höchst merkwürdig: ich kann vom server (10.16.1.1) aus den switch (10.16.1.253) anpingen und nmap zeigt auch: “open ports 22 und 443” (so wie es eingestellt ist). Aber weder ssh noch https:// liefern dann eine Antwort. Verstehe ich nicht – passt aber zum Bild, dass auch dhcp keine Adresse ausliefert. Der Fehler liegt aber vermutlich im Switch oder was meinst du?
das ganze klingt für mich sehr nach einem vollen ARP Cache auf dem Cisco.
Ein reboot würde ihn leeren … und es ist nur eine Frage der Zeit, bis
er wieder voll ist.
Du kannst ihn hoch setzen: aber leider nur wenig.
Ich hatte das Problem und hab es durch hochsetzen gelößt… bis mein
Netz zu groß wird.
Dann wir ein neuer L3 Switch mit einem größeren ARP Cache her müssen.
An der Stelle merkt man, dass der SG300 ein „kleiner“ von Cisco ist …
unten ist meien Mail von damals.
LG
Holger
Hallo,
das klingt ganz nach dem Problem, das ich letztes Jahr hatte - hast Du
die maximale Anzahl der Listeneinträge der TCAM entries schon
hochgesetzt? Findet sich unter ‚Administration → Routing Resources‘,
die ist werkseitig (für uns) zu niedrig, ich habs auf 256 Einträge
gestellt, seitdem gab es das Problem nicht mehr.
Viele Grüße,
Marcus
Hallo alle zusammen,
ich hab mal eine hochkarätige Frage: vielleicht ist ja ein
„Switchversteher“ dabei.
Mein Netz ist mit Hilfe eines Cisco SG300-10 segmentiert seit ca. 1,5
Jahren.
Alles läuft super mit unseren >160 Rechnern.
Vor 3 Wochen hatte ich aber plötzlich das Problem, dass die manche
(nicht alle!) Clients zwar beim PXE Boot eine IP bekamen, aber linbo
bekam keine und zeigte OFFLINE an.
Es war aber auch nicht nur ein Segment betroffen.
Das ganze wurde erst behoben, nachdem ich den Cisco rebootet hatte.
„Einmal ist keinmal“ dachte ich mir (oder besser: hoffte ich).
Gestern trat es aber wieder auf.
Also rebootete ich den Cisco und schaute in die Logdateien.
Da fand ich sehr viele solche Einträge:
Error %ARP-E-ARPTBL: ARP Table Overflow
Heute hab ich mal nach dem Fehler im Netz gesucht.
Dabei fand ich diese Seite:
Hmm. Dann müsste es nach einem Neustart des Switch aber für den Moment OK sein, war es aber nicht?!? Zudem klappt es immer im Servernetz aber nicht in allen anderen VLANs, die der Server bedient…
neuer L3 Switch mit einem größeren ARP Cache her müssen
Auch ein Cisco? Welchen hast du denn da genommen? Ich würde natürlich die bestehenden Konfigurationen einfach einspielen wollen, daher müsste der kompatibel sein…
Hi nochmal.
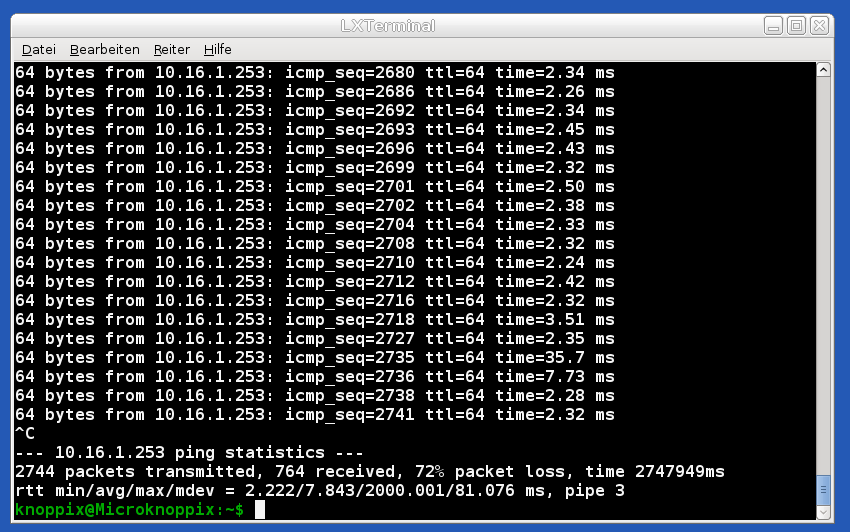
Vielleicht ein Anhaltspunkt … ich habe aus einer VM, die im Servernetz hängt (und ja seltsamerweise ihre IP-Adresse korrekt erhält!) einen ping auf den L3-Router abgesetzt. Hier das Ergebnis:
Das sieht ja erstmal fast normal aus – doch zwischen den einzelnen pings stockt alles. Es dauert gefüht eine Ewigkeit (zurückversetzt in Zeiten von 2400 Baud Modems) bis der nächste Ping abgeschickt wird.
Vielleicht deutet das auf eine defekte Netzwerkkarte (i350-4 als 4-fach bond0 eingerichtet) hin?? Oder hängt das bond.0 selbst evtl nicht richtig am Switch?
Ich weiß – man bräuchte eine Glaskugel aber vielleicht ja jemand etwas ähnliches schon mal gehabt und eine Idee, wo man da suchen soll…?
Frustrierte Grüße,
Michael
ich hab KEINE Erfahrung mit dem Bonding am Layer3-Switch bei Proxmox, könnte mir aber vorstellen, dass das Bonding Probleme mit sich bringt (Flaschenhals-Problematik für andere Netzwerkbereiche, Probleme beim Bond-Erstellen selbst).
Daher würde ich auch:
Das Log-File des cisco auswerten !
Unbedingt überprüfen, ob Du das dhcp-Relaying korrekt installiert hast (!)
(Konfiguration abspeichern nicht vergessen, damit nach einem reboot alles noch da ist !)
Evtl. Proxmox neu starten. Ich weiß das nicht genau, aber sollte dann nicht auch der Hypervisor die Bonds neu initialisieren ? Dann würd ich das machen, danach die VMS nacheinander hochfahren (Ipfire, Pause, Server, Pause,…)
Weitere Probleme können sein: Kaskadierte Switches (da muss man offenbar das spanning tree-Protokoll anpassen, Stichwort “Root Switch”)
Kabelprobleme, Hardwaredefekt an Netzwerkkarte (wie von Dir vermutet)
Guten Morgen.
Ich habe das Problem so gelöst, dass ich das bond0 jetzt auf den Backup-Server gelegt habe. Damit lief es wieder. Zuvor hatte ich (vor längerer Zeit!) ein Proxmox-Upgrade auf 5.2.x gemacht. Scheinbar hängen die Probleme damit zusammen. Im Log-File (dmesg) findet sich auf dem Produktivserver:
bond0: option mode: unable to set because the bond device is up
Das erklärt, warum das bond.0 so seltsam reagiert und nicht vollständig konfiguriert ist.
Warum der Fehler aber seit V5.x überhaupt besteht, ist noch offen. Das frage ich mal im Nachbarforum …
super, dass Du das Problem abfangen konntest. Vielleicht hat ja nach dem Update Deines Proxmox-Servers das Bond begonnen, zu “klemmen”. Wenn Du aus dem anderen Forum die entsprechende Komplettlösung erfahren hast, wäre es sehr nett, sie hier bei uns noch zu posten.
Ich glaube nämlich, dass es Sinn macht, neben der Xen-Virtualisierung auch noch die KVM-Lösungen für die Linuxmuster.net zu “pushen” (meine Privatmeinung !). Und das Proxmox-Environment ist schon ein recht cooles, wie ich meine, indem es auch sehr umfangreiche Möglichkeiten integriert, wie z.B. das Container-Managment, das Clustering, die Live-Migration, das Anbinden verschiedenster (Netzwerk-)Dateisysteme, auch verteilt, das “easy”-Bonding u.v.a.m.
Im Gegensatz zu Xen wird kein Kernelpatch benötigt, bei KVM kann man immer direkt auf den neuesten Kernel vertrauen und muss keine Angst vor kernelbasierten Unverträglichkeiten haben usw. usf.
Daher sind Problemstellungen & Lösung hier im Forum m.E. sicherlich hochwillkommen.
Ja, ich gehe im Moment davon aus, dass das Upgrade von 4.4 auf 5.2 den Fehler mitgebracht hat. Die Hardware ist nicht mehr die aller neueste. Es ist ein GigaByte-Mainboard von 2013 mit einer 8-Core-CPU. Lief eigentlich bisher immer anstandslos. Das Upgrade lief zwar fehlerfrei durch, doch diesen Effekt hatte ich vor einiger
Zeit schon mal (da waren allerdings Ferien und es hat nicht so gebrannt wie heute). Da hatte ich es auf den Switch geschoben, denn nach einem Neustart des L3 war alles wieder ok. Dieses Mal half das aber leider nicht, so dass ich tiefer graben musste. Und da auch ein Neustart des Hypervisors nichts gebracht hat, habe ich mich auf einen kompletten Umzug auf unser (etwas schwächeres) Backup-System vorbereitet. Heute Morgen musste ich dann nur noch die 4 Strippen vom bond.0 auf den Backup-Server legen und den Switch einmal neu starten und „schon“ war alles so wie zuvor. Das gute an der Sache ist, dass unser desaster-Masterplan funktioniert – das schlechte daran ist, dass ich den Fehler auf dem Produktivserver bisher trotzdem nicht richtig einordnen kann und dass dafür natürlich wieder Stunden und Nerven drauf gegangen sind …
… ich nehme an, dass das bond.0 beim Systemstart aus irgendeinem Grund nicht (mehr) richtig konfiguriert werden konnte. Warum auch immer?!? Jedenfalls deutet die Meldung in den Logfiles sowas an. Die Hardware ist meiner Meinung nach in Ordnung, denn warum sollte sonst in diversen VLANs alles ok sein und in anderen nicht? Es sieht für mich so aus, als wären eine oder zwei Leitungen des LAGs benutzt und der Rest nicht – so reime ich mir auch die lange Dauer beim ping zusammen (der dann evtl nochmal über eine andere der 4 Leitungen geschickt wird)??? Aber das sind alles nur Vermutungen … meine Suche hat bisher nix konkretes ergeben.
Dennoch: Ich finde Proxmox als Hypervisor ebenfalls genial und sehr gut zu bedienen. Daher bleiben wir auch dabei und wechseln nicht zu Xen. Aber das ist ein anderes Thema …
Schöne Grüße,
Michael